 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Differentiation for Tackling Challenges in Watermarking Low-Entropy Constrained Generation Outputs
Jan 14, 2026We demonstrate that while the current approaches for language model watermarking are effective for open-ended generation, they are inadequate at watermarking LM outputs for constrained generation tasks with low-entropy output spaces. Therefore, we devise SeqMark, a sequence-level watermarking algorithm with semantic differentiation that balances the output quality, watermark detectability, and imperceptibility. It improves on the shortcomings of the prevalent token-level watermarking algorithms that cause under-utilization of the sequence-level entropy available for constrained generation tasks. Moreover, we identify and improve upon a different failure mode we term region collapse, associated with prior sequence-level watermarking algorithms. This occurs because the pseudorandom partitioning of semantic space for watermarking in these approaches causes all high-probability outputs to collapse into either invalid or valid regions, leading to a trade-off in output quality and watermarking effectiveness. SeqMark instead, differentiates the high-probable output subspace and partitions it into valid and invalid regions, ensuring the even spread of high-quality outputs among all the regions. On various constrained generation tasks like machine translation, code generation, and abstractive summarization, SeqMark substantially improves watermark detection accuracy (up to 28% increase in F1) while maintaining high generation quality.
Are Large Language Models Robust Zero-shot Coreference Resolvers?
May 23, 2023



Recent progress in domain adaptation for coreference resolution relies on continued training using annotated data from target domains. At the same time, pre-trained large language models (LMs) have exhibited strong zero- and few-shot learning abilities across a wide range of NLP tasks including pronoun resolution. While this demonstrates evidence of coreference ability, previous work has mostly studied this ability using simple sentence-level datasets such as the Winograd Schema Challenge. In this work, we assess the feasibility of zero-shot learning for coreference resolution by evaluating instruction-tuned language models on more difficult, linguistically-complex coreference benchmarks (e.g., CoNLL-2012). We demonstrate that zero-shot prompting outperforms current unsupervised coreference systems. Further investigations reveal the robust zero-shot generalization ability of instruction-tuned LMs across a wide range of domains, languages, and time periods, as well as a strong reliance on high-quality mention detection systems.
Few-Shot Anaphora Resolution in Scientific Protocols via Mixtures of In-Context Experts
Oct 07, 2022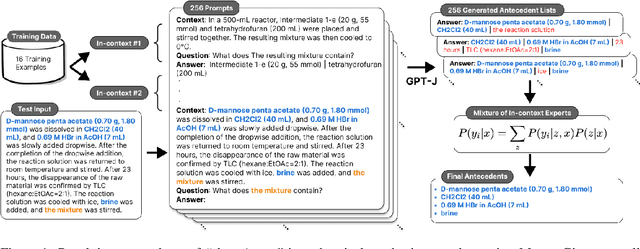
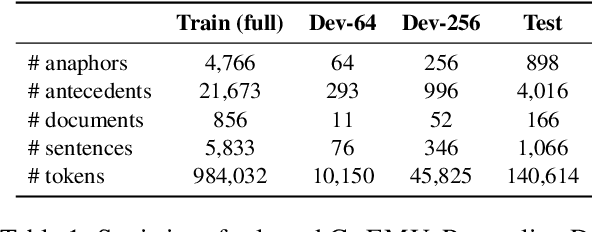
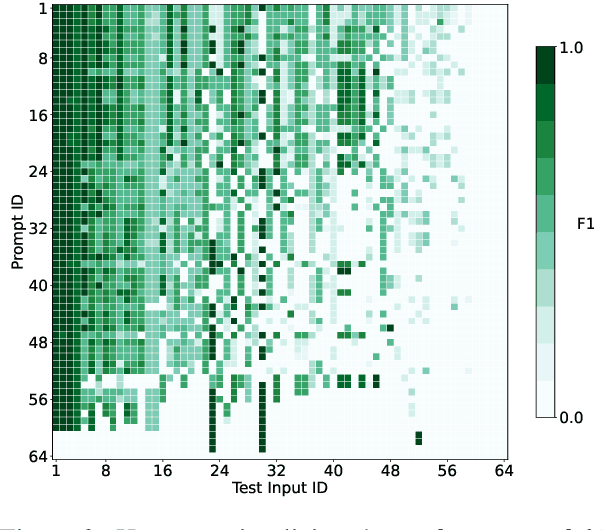
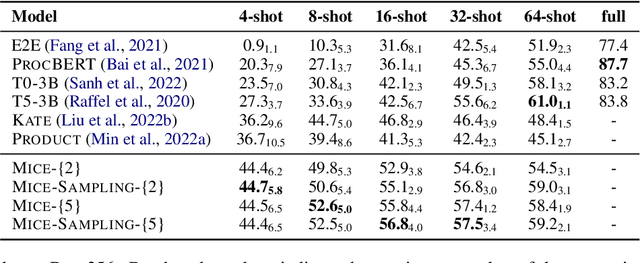
Anaphora resolution is an important task for information extraction across a range of languages, text genres, and domains, motivating the need for methods that do not require large annotated datasets. In-context learning has emerged as a promising approach, yet there are a number of challenges in applying in-context learning to resolve anaphora. For example, encoding a single in-context demonstration that consists of: an anaphor, a paragraph-length context, and a list of corresponding antecedents, requires conditioning a language model on a long sequence of tokens, limiting the number of demonstrations per prompt. In this paper, we present MICE (Mixtures of In-Context Experts), which we demonstrate is effective for few-shot anaphora resolution in scientific protocols (Tamari et al., 2021). Given only a handful of training examples, MICE combines the predictions of hundreds of in-context experts, yielding a 30% increase in F1 score over a competitive prompt retrieval baseline. Furthermore, we show MICE can be used to train compact student models without sacrificing performance. As far as we are aware, this is the first work to present experimental results demonstrating the effectiveness of in-context learning on the task of few-shot anaphora resolution in scientific protocols.